
Folio F1R’s wonderful roots and tokens – First Voynich Manuscript’s folio
Table of Contents
Folio F1R is calling, now or never it is… We all want to know what the Voynich MS hides in its entrails. At least, I do… But little did you know that the first page actually has a lot to say on its own, right? With its 28 lines and 177 spaces, that amounts to 206 words in total. How much is that to chew? Not a lot at all. But since words have building blocks, we expect to find some of those in the first page… Right? Of course… If you haven’t seen my earlier video, go check it out in the YouTube corner as suggested. Let us see why Folio F1R has amazing roots and tokens.

Folio f1r of Voynich Manuscript reveals amazing roots and tokens
As I said previously, the symbols that appear in the Voynich MS reveal a clear glyph structure that is based on seven symbols and one repeating symbol, or so… How on Earth do you expect to study the manuscript if you fail to recognize this aspect? Thankfully, I have revealed it in my previous videos. Now, I want you to picture this…
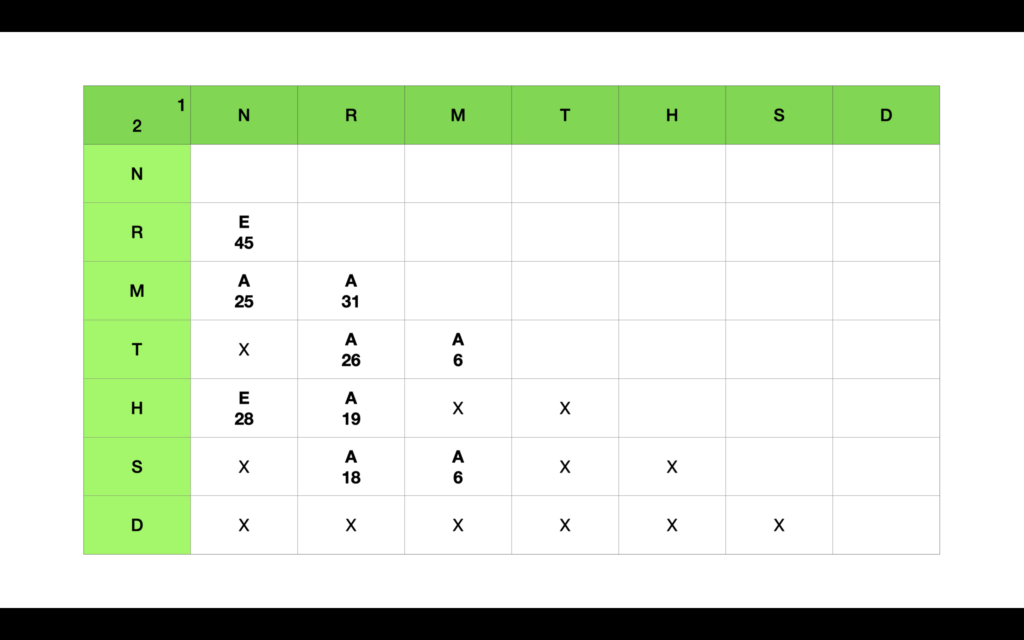
As I was hearing the first video I made about folio F1R, it seemed clear that there are some roots and tokens that you can discern. Keep a close attention and you will see that things like Ner, Neh, and Ram, repeat ever so often. Here is a summary table of consonant one vs. consonant two and statistics of occurrence of a vowel between them.

More concise data
As evidenced by Table 1, there is a recurrent referral from line 1 consonants to column 2 consonants in a triangular shape. So, for example, ‘Ner’ would occur a significant number of times, namely 45. Whereas ‘Ren’ would never occur as significantly. So, when a combination C1VC2 occurs, the combination C2VC1 does not seem to be part of the language. Also, the most common letters as vowels within word roots and tokens are A and E. In the next table, we keep only the significant bit of every combination.
Main syllable components
What I suggest from the Table 2, using the symbol X, is that those combinations C1VC2 are possible and will appear in the language. Owing to scientific research what I know of the matter, I want to make this bold statement: “The JP system will reveal in due time all tokens that are marked as X”. As a rule of thumb, I will suggest also that in every corner of the manuscript, word roots and tokens will assemble as C1 A C2, or C1 E C2, that is with A and E vowels.
Towards solving the mystery…
If any vowel comes between the two consonants, the syllable will not be regarded as a root or a token. Either we make it or we break it. But we need to brute force our way into solving this mystery. My idea here is that, if you have to build a language, you are prone to put rules that give you less freedom. And by that token, you’d have to respect those rules if you want to be any successful. In the next table, we can see how, out of 206 words, there are a few roots and tokens that appear most of the time.
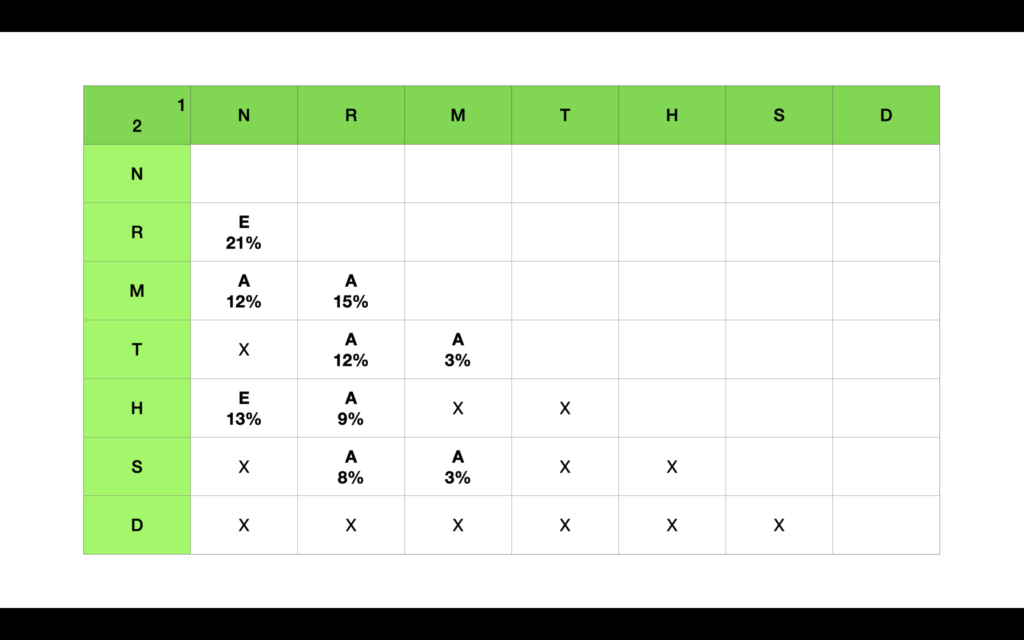
The ratio has been calculated as (number of appearances of root) over (number of words). The ratio is a score rather than a percentage. This is because, a word can contain many roots, and a root can appear many times in the same word. Don’t get me wrong, even as low as 3% for a root such as MAS or MAT is significantly large. Remember that we are dealing here with a language, and anything beyond 0.5% is something of importance.
A real world example
Just calculate the ratio for the word ice in this content, and picture that I said it only once in all of this conversation. So you’d expect it to have a very low occurrence, given the total number of words. Meanwhile, if an extraterrestrial doesn’t recognize that that secret word I said is indeed a word, I won’t blame him. I would much rather have him understand things such as pronouns and movement verbs, than things such as physical states of water.
FSG’s scramble of death vs. the JP system
Here, I want you to picture how the FSG system scrambles my word roots so that I lose all control over deciphering the content. The diagram shown here is a proof of concept of why FSG might be the pain dealer.

Diagram 1’s first line displays the word ‘matinero’ that appears in my JP voice-over video. As I picked and chose the roots, it so happens that ‘MAT’ in yellow and ‘NER’ in green are roots. In the FSG system, they would appear like shown in line 2. So the root MAT gets interleaved with an I, which will break the meaning. The root NER will get interleaved with an O, which also deals a knockout to the meaning. Convinced? Or, not yet?…
A significant analysis…
If the word ‘matinero’ is significant, you will often see the combination ‘TEN’ also, which would suggest that it is a root. So, you’ll miss the idea that it is made out of parts of two roots. That is all you need to know for now.

Again, in Diagram 2, you can see what happens to roots. You seem to get two-letter roots, which is not what you would expect. You also have three-letter scrambled roots that arrange themselves in couples. So it is even harder to extract information from such words. In this example, the three-letter components that combine two roots are SEN and MAN. The two-letter components that is only a part of a root is ‘AR’. Didn’t I say that folio f1r has amazing roots and tokens? What do you expect?
If you lose information, you doom yourself to stay in the gibberish zone. We want to decode the manuscript now or never. This is the purpose of this channel, so stay tuned for more.
2 thoughts on “Folio F1R’s wonderful roots and tokens – First Voynich Manuscript’s folio”
Comments are closed.